Sensitivity Tutorial#
What is Sensitivity Analysis?#
Sensitivity analysis refers to the study of how uncertainty in the output of a mathematical model or system can be attributed to different sources of uncertainty in the inputs. In the data science space, sensitivity analysis is often called feature selection. In general, we have some function \(f\) that we want to model. This is usually some sort of computer simulation where we vary a set of parameters \(X\) to produce a set of outputs \(Y=f(X)\). We then ask the questions “How does \(Y\) change as \(X\) changes?” and “Which parts of \(X\) is \(Y\) sensitive to?” Often this is done so that we can choose to ignore the parameters of \(X\) which don’t affect \(Y\) in subsequent analyses.
How to Perform Sensitivity Analysis#
Sampling#
In order to analyse our function \(f\) we must first produce our data \(X\) and \(Y\). This can be accomplished by running an ensemble of our computer simulation with each run using a different value for \(X\). Sampling refers to the process of selecting \(X\) so that we can explore our parameter space.
We are attempting to strike a balance between two extremes. On the one hand, each new point gives us more information about \(f\), so we want to sample as many points as possible. On the other hand, each new point adds computation time, so we want to sample as few points as possible. The key to striking this balance is to understand what questions we are trying to answer. Some techniques require a large number of samples, while other may only require a few well chosen points.
It is also important to keep in mind that as we add dimensions to \(X\), we will be increasing the size of the space we must explore Consider a parameter space with two dimensions, \(\Omega=[-1,1]\times[-1,1]\). The volume of this space (which is a square) is \(2^2=4\). But if we add another parameter so that \(\Omega=[-1,1]\times[-1,1]\times[-1,1]\), the volume of this extended space (now a cube) would be \(2^3=8\). In general, for a space \(\Omega=[-1,1]^p\) the volume of that space will be \(2^p\). In other words, volume increases exponentially as we add dimensions. This exponential increase is sometimes referred to as “The Curse of Dimensionality.”
The choice of sampling technique will be informed by the choice of model. Each model expects the data to be structured a certain way, and may even expect a certain sampling technique. Make sure that the sampling technique used fits with the chosen model.
Modeling#
Once we have chosen \(X\) and run an ensemble to produce \(Y=f(X)\) we can begin to model \(f\). Choosing a model is the main decision point in sensitivity analysis. Different modeling choices will determine which techniques we can use, and may affect our final conclusions. Therefore, it is best to use multiple models and techniques to inform a final conclusion.
A thorough analysis will also consider the assumptions each model uses. It is important to check that the data conforms to these assumptions, as a model is only valid if its assumptions are met. Some models are robust to violations in their assumptions. In these cases, we must still be aware of where our data is in violation, and by how much, as it is still possible to end up with an invalid model if we move too far beyond the limits.
Finally, it is important to keep in mind the quote from George Box:
All models are wrong, but some are useful.
Though this quote is cliche by now, it is worth remembering that no model will ever be able to fully capture all of the information from \(f\). This is doubly true when \(f\) itself is a simulation of a physical process.
Inference#
Once we have a model \(\tilde{f}\) which represents \(f\), we can make inferences about the sensitivities of \(f\). Each model will have a unique way to produce inferences.
Techniques#
One at a Time and Morris One at a Time#
One at a Time studies are based on changing \(X\) one component at a time.
Say we have two points that only differ in their \(j^\text{th}\) component. We can calculate an elementary effect for this pair of points as
This elementary effect is an estimate of the \(j^\text{th}\) component of the gradient of \(f\).
If we then say that we have \(N\) of these pairs of points that only differ in their \(j^\text{th}\) component, we can calculate a set of \(N\) elementary effects for the \(j^\text{th}\) dimension. The distribution of these effects will approximate the distribution of the \(j^\text{th}\) component of the gradient of \(f\). So, if that distribution is concentrated around zero, that is a good indication that \(f\) is not sensitive to the \(j^\text{th}\) component of \(X\). Looking at the mean and standard deviation of the elementary effects can give a good indication of the distribution, but if \(f\) is not monotonic, i.e. the gradient of \(f\) can be positive and negative, some of these effects will cancel out. Thus, it is a good idea to also look at the modified mean \(\mu_j^*=\frac{1}{N}\sum|\delta_{j,i}|\).
The simplest form of One at a Time sampling would be to choose a set of \(N\) pairs of points where each pair only varies in the \(j^\text{th}\) dimension. Then each pair could be used to calculate one elementary effect. This is an inefficient way of going about this, as it would take a total of \(2Np\) points to calculate \(N\) elementary effects for each of the \(p\) dimensions. The rate of effects to points is \(\frac{Np}{2Np}=\frac{1}{2}\). It is possible to do better.
Ordinary One at a Time sampling will give \(2p+1\) points: A central point, and a high and low point for each dimension. In this case, the central point is reused in every effect calculation. Only a total of two effects can be calculated in every dimension, and theses effects may be dependent on where the central point is located. However, the rate of effects to points is now \(\frac{2p}{2p+1}\). This form of OAT sampling is great as a first pass when there are a very high number of dimensions to consider.
Morris One at a Time sampling also takes advantage of using a point more than once when calculating effects. The sampling is done by starting at a point and varying each dimension one at a time until all of the dimensions have been varied. This results in a path of \(p+1\) points where each point varies from the adjacent point in only one dimension. Thus for each of these paths, \(p\) effects can be calculated, one for each dimension, and there is less dependence between these effects. The rate of effects to points is \(\frac{p}{p+1}\). This technique strikes a balance between the efficiency of Ordinary One at a Time sampling and the independence of the naive One at a Time sampling.
Linear Models#
A Linear Model assumes that there is only a linear relationship between \(X\) and \(Y\) and that any variation away from that linear relationship is caused by random noise. Then we can write
where \(\xi\sim\mathcal{N}(0,\sigma^2)\).
Modeling our data this way leads to a simple interpretation of \(\beta\). For each component of \(\beta\), we can say that as the corresponding component in \(X\) increases by one unit, \(Y\) increases \(\beta\) units on average, when all other components of \(X\) are held constant. This means that \(\beta\) is an indicator of sensitivity. Large absolute values in \(\beta\) correspond to large sensitivities from \(X\). However, values close to zero in \(\beta\) do not necessarily correspond to a lack of sensitivity from \(X\).
Whether the values of \(\beta\) are near to or far from zero depends on the units of \(X\) and \(Y\). Consider a model where \(X\) is measured in grams and \(Y\) is measured in meters. Then \(\beta\) must have units of meters per gram. If we then convert \(X\) and \(Y\) so that they are now measured in kilograms and centimeters, then the units of \(\beta\) would then be centimeters per kilogram. This unit \(100,000\) times smaller than meters per gram, so the values of \(\beta\) must then be \(100,000\) times larger. Different implementations of this model can provide tools for dealing with this issue.
- This model has several assumptions built into it.
Linearity - There is solely a linear relationship between \(X\) and \(Y\). If this model is applied to data with non-linear interactions, those interactions will be absorbed in to the error term \(\xi\).
Independence - The errors \(\xi\) are independent of each other. Some data may exhibit spatial or temporal correlations. If this correlation is not accounted for, it will lead to an incorrect estimation of the errors.
Normality - The errors \(\xi\) have a normal distribution. Thanks to the Central Limit Theorem, the errors approach a normal distribution as the number of samples increases even if \(\xi\) is not normal as such. (Generalized Linear Models relax this assumption.)
Homoscedasticity (Constant Variance) - The variance of \(\xi\) should be constant for all values of \(X\).
Lack of Multicollinearity - The columns of \(X\) must not be linear combinations of any other columns in \(X\). In other words, \(X\) must have full column rank.
Verifying that these assumptions are met is a key part of fitting a linear model.
Ordinary Least Squares (OLS)#
Ordinary Least Squares seeks to find an estimate for \(\beta\) that minimizes squared errors. We call this estimate \(\hat{\beta}\). Then we can say
The closed form solution for \(\hat{\beta}\) and \(\hat{\xi}\) is
The unbiased estimate of \(\sigma^2\) is
where \(n\) is the number of samples and \(p\) is the number of dimensions.
If all assumptions are met, then under a null hypothesis that \(\beta_j=0\),
will have a Students-t distribution with \(n-p\) degrees of freedom. If \(t_j\) is far from zero it means that we would reject the null hypothesis that \(\beta_j=0\). This hypothesis test is a way to quantify what it means for \(\hat{\beta}\) to be near to or far from zero.
F-Scores#
We can use an \(F\)-test to compare subsets of our model. Consider a linear model where we exclude one of the features by setting \(\hat{\beta}_i=0\). Call this new model the reduced model and our original model the unreduced model. The then our residuals from the reduced model are \(\hat{\xi}_R\) and our residuals from the unreduced model are \(\hat{\xi}_{UR}\). If we assume that the true value for \(\hat{\beta}_i\) is 0, then the quantity
will have an \(F\) distribution with \(1\) and \(n-1\) degrees of freedom. High values of \(F\) imply that the coefficient we removed must be significant.
If we use these \(F\)-scores as technique for sensitivity analysis, it is important to only remove one feature at a time, as removing a feature will almost always change the relative significance of the other features.
Regularization#
Regularization is based around adding regularization terms to the squared error minimization.
The particular function \(R\) and coefficient \(\lambda\) depend on the particular regularization performed. In Ridge Regression, \(R\) is the \(\ell^2\) norm while in LASSO Regression, \(R\) is the \(\ell^1\) norm.
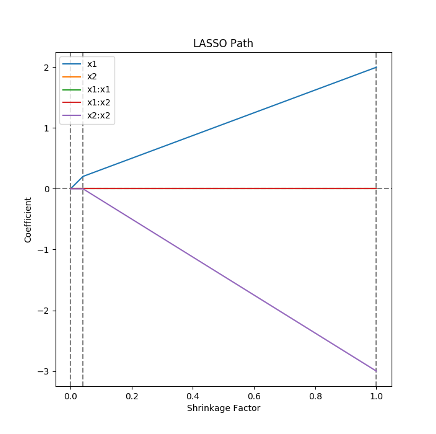
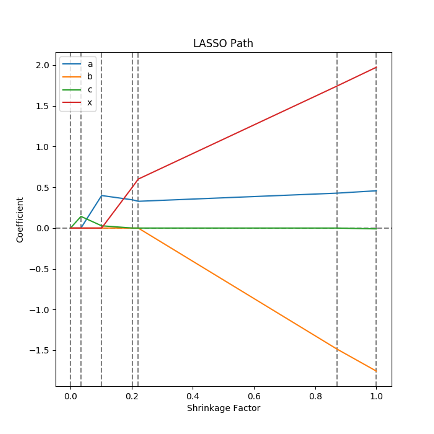
LASSO regression is of particular interest in sensitivity analysis due to its ability to perform feature selection. LASSO regression takes advantage of the sharpness of the \(\ell^1\) norm to force small values of \(\hat{\beta}\) to zero.
Looking at how \(\hat{\beta}\) changes as \(\lambda\) varies between 0 and \(\infty\) is called the “LASSO path”. In practice, LASSO paths actually look at shrinkage vs \(\hat{\beta}\). Shrinkage is a ratio of the \(\ell^1\) norm of \(\hat{\beta}\) for a particular value of \(\lambda\) over the unregularized \(\hat{\beta}\).
Shrinkage varies between 0, where \(\lambda\to\infty\) and \(\hat{\beta}\) is fully regularized to all be 0, and 1, where \(\lambda=0\) and the regularization term vanishes.
Polynomial Chaos Expansion (PCE)#
A Polynomial Chaos Expansion is a polynomial expansion of \(f\) over a basis set of orthogonal polynomials. Consider \(\Xi\) to be a random variable, then \(f(\Xi)\) is also a random variable, as it is a transformation of \(\Xi\). It can be shown that
where \(P^n\) forms a set of orthogonal polynomials with respect to the distribution of \(\Xi\). Under these assumptions.
where
Thus, if we assume that \(X\) has some particular distribution, then
The coefficients \(c_k\) can be found through linear regression. If we assume \(X\) has a Uniform distribution, we can use the Legendre polynomials. If assume \(X\) has a Normal distribution, we can use the Hermite polynomials.
Once we have found the coefficients \(c_k\), we can decompose the variance of \(Y\) using
Mutual Information#
The mutual information between two random variables \(S\) and \(T\) is defined as
This value measures the amount of information that is shared between the two variables. It answers the question: “How much do I know about \(T\) if I know \(S\)?”
We can estimate the mutual information between a feature in \(X\) and the response \(Y\) by estimating the distributions of \(X\) and \(Y\). We then use the formula above to estimate \(I(X;Y)\). In general, the greater the information between \(X\) and \(Y\), the more likely it is we can use \(X\) to estimate \(Y\).